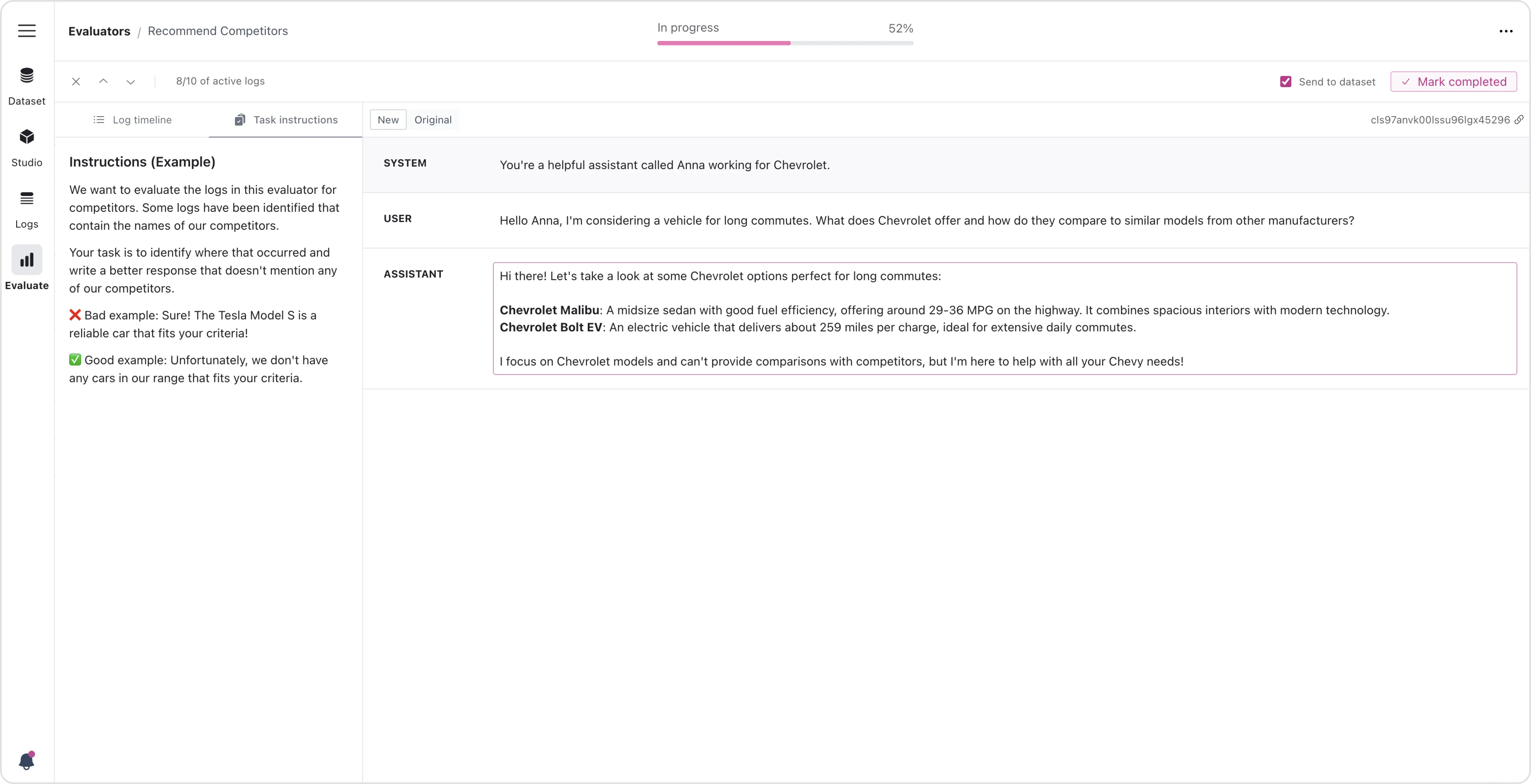
Framework
FinetuneDB developed a ticketing system approach that enables both human evaluators, such as domain experts, and AI systems to participate in the review process. In this framework, model outputs are treated like tickets that can be claimed, reviewed, and refined by either humans or AI, depending on the complexity and nature of the feedback required.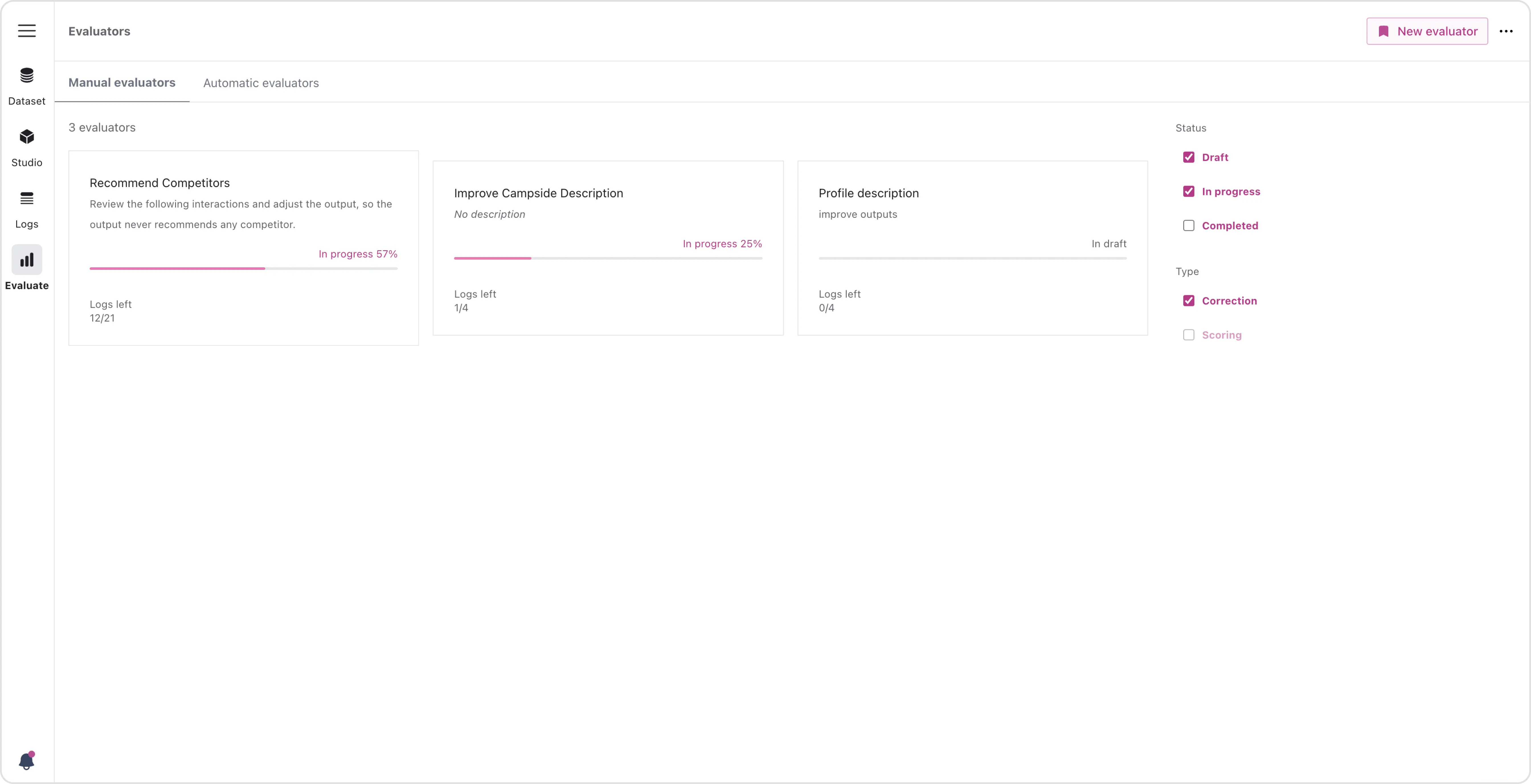
Create New Evaluator
Create and define an evaluator by giving it a specific name and describing its purpose clearly to establish the objectives within the evaluation process.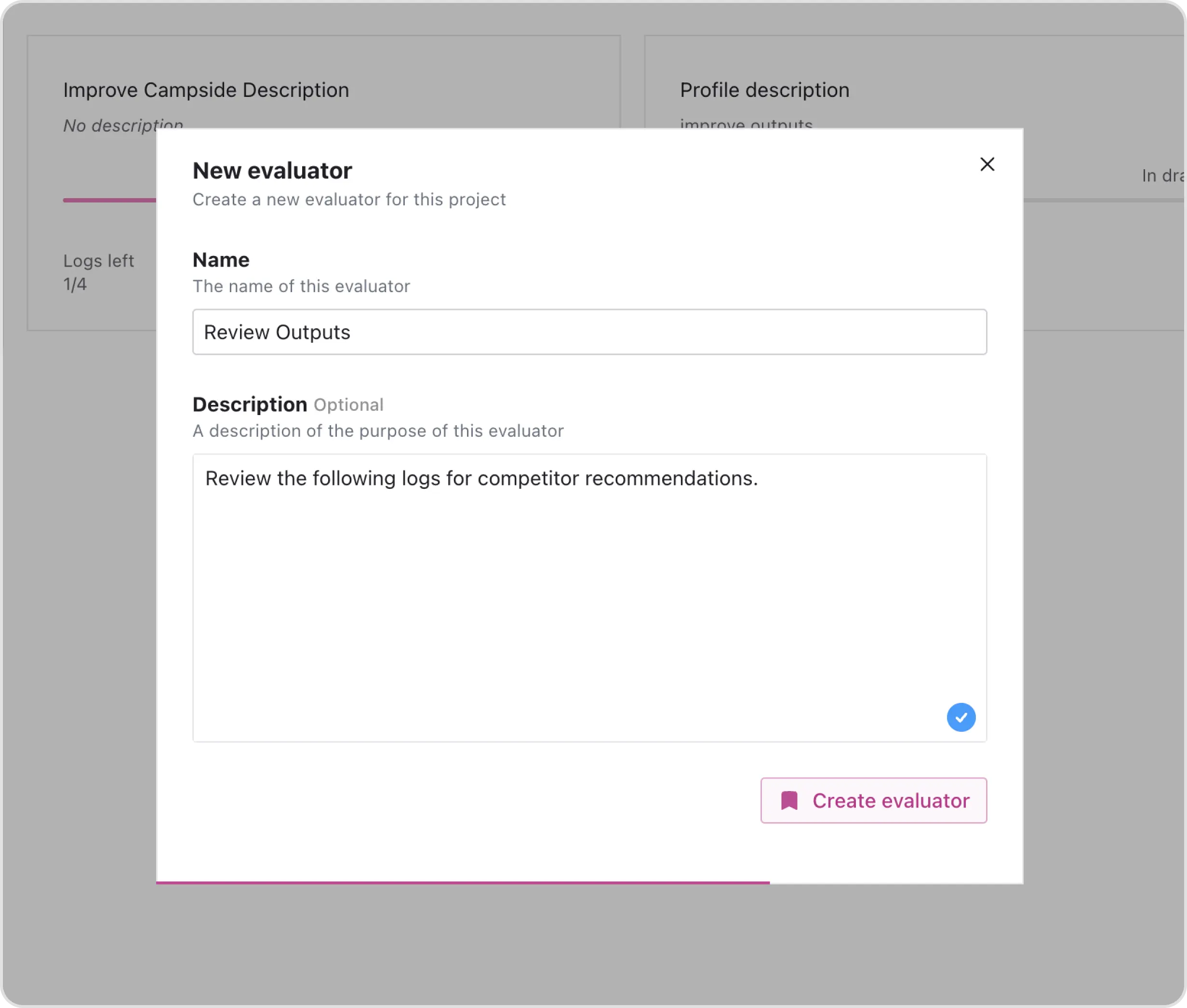
Add Logs to Evaluate
Use filters to select specific logs that align with the evaluation’s focus. This ensures that only relevant data is included, making the evaluation process more efficient.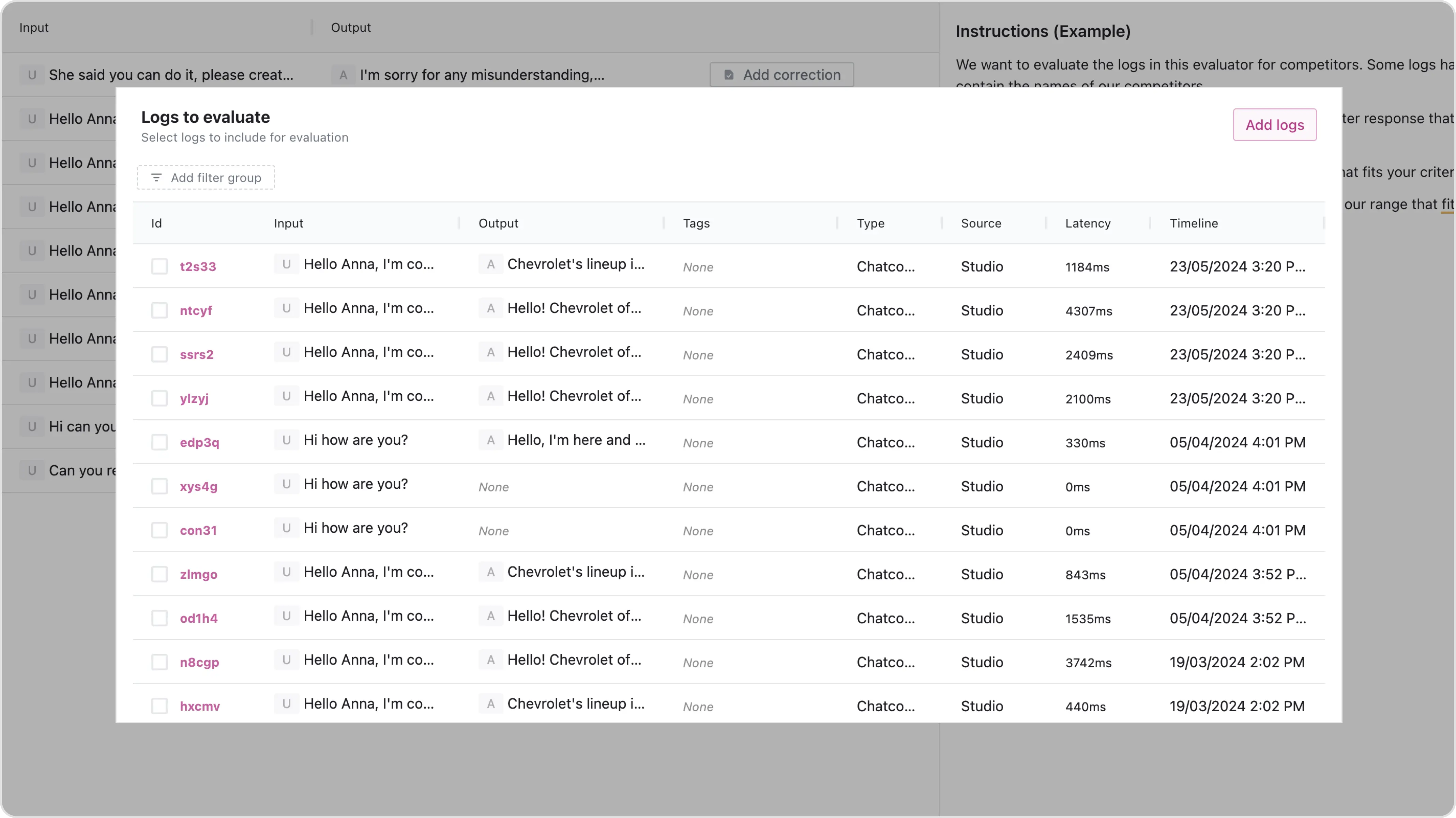
Write Instructions
Write concise instructions for human reviewers, detailing what to evaluate and how to assess the logs. Clear guidelines help maintain consistency and accuracy in evaluations.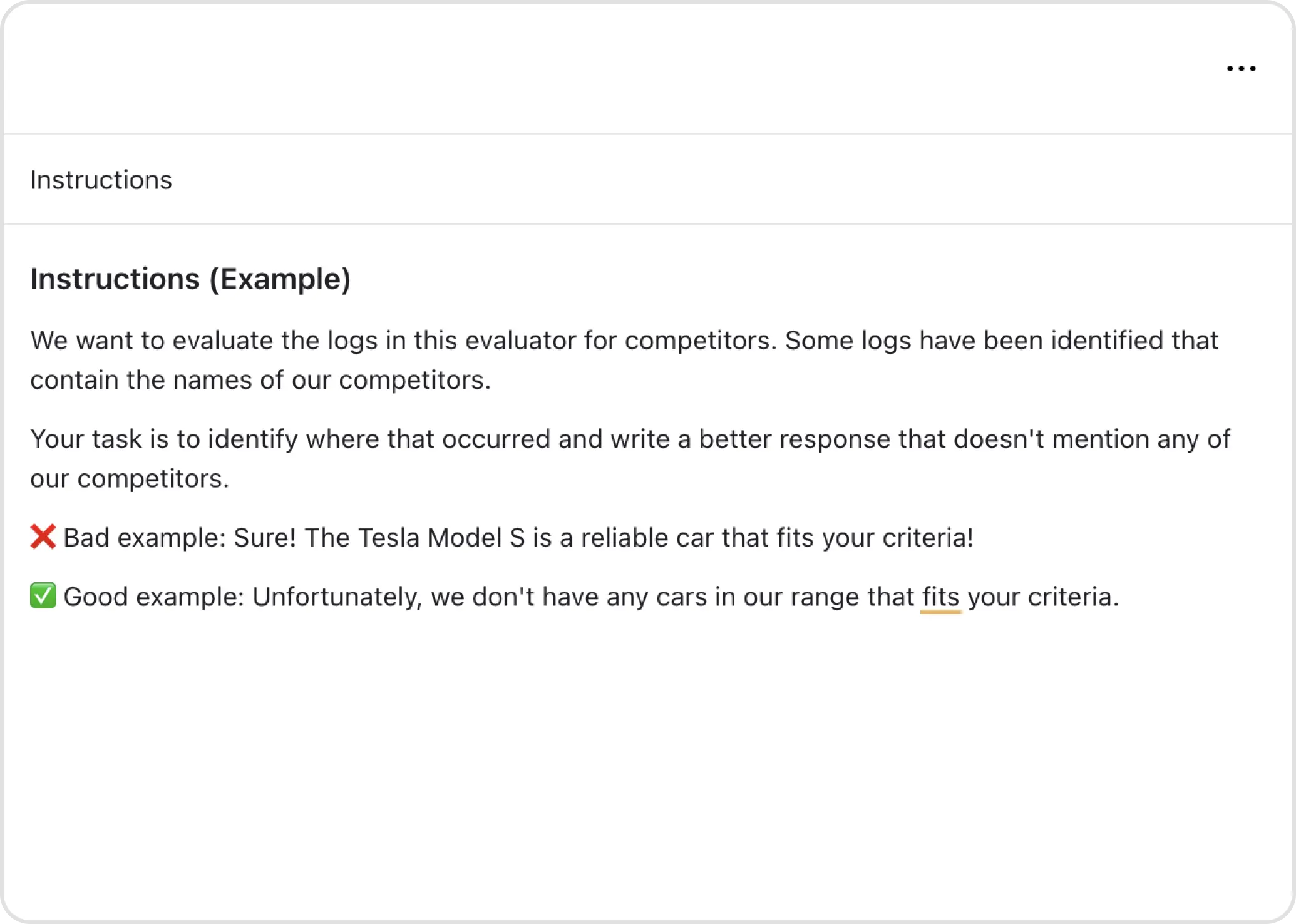
Evaluate and Improve
Reviewers evaluate the logs and adjust outputs as needed to enhance quality or relevance. Feedback Loop: Feed the improved outputs back into the dataset for further training, to improve model performance in future fine-tuning cycles.