ContentBoost’s Use Case
ContentBoost specializes in AI-driven content creation for SEO and marketing purposes. Their traffic is growing fast, and by switching to an open-source model, their goal is to reduce costs while maintaining high performance for their content creation use case. This guide follows ContentBoost as they transition from using GPT-4 Turbo to an open-source model.Step 1: Track Production Logs
ContentBoost sets up to tracking their application’s production logs on FinetuneDB. They follow the steps outlined in the Logging Data guide to integrate the FinetuneDB SDK and begin logging data. This allows them to capture all interactions, which serves as the baseline dataset for fine-tuning.Integration
Start tracking production data by quickly integrating FinetuneDB.
Step 2: Access Production Logs
ContentBoost navigates to the Log Viewer on the FinetuneDB platform, where all their production logs are captured. They aim to start with about 500 logs for their first fine-tuning dataset, and depending on their traffic, collecting enough logs may just take a few days. These logs include interactions such as generating SEO-optimized blog posts and marketing copy.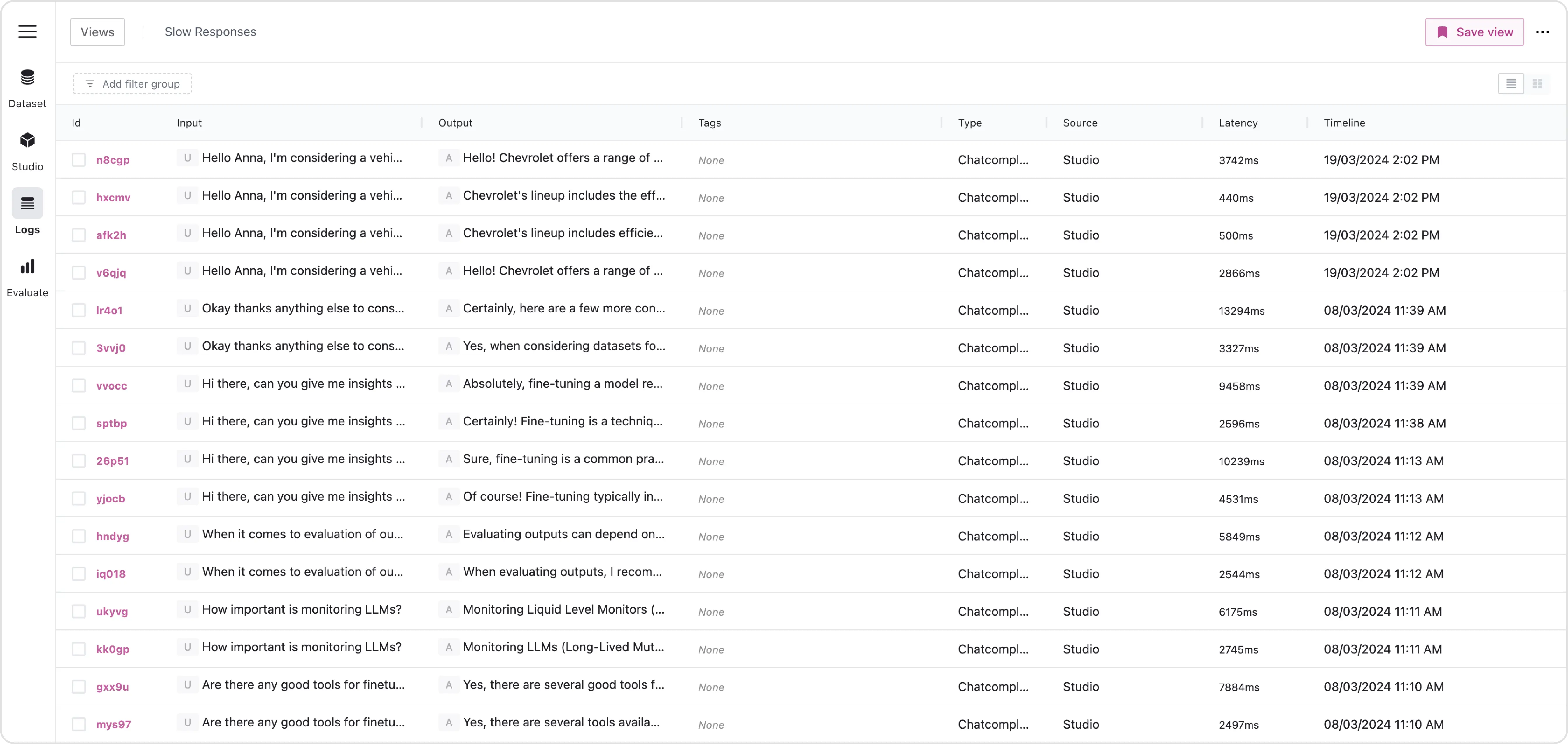
Step 3: Filter and Select Logs
ContentBoost select the logs that represent successful interactions and responses, focusing on those that produced high-engagement content. To streamline this, they filters logs based on relevant criteria, such as completion ID, model, and custom tags (e.g. high engagement article).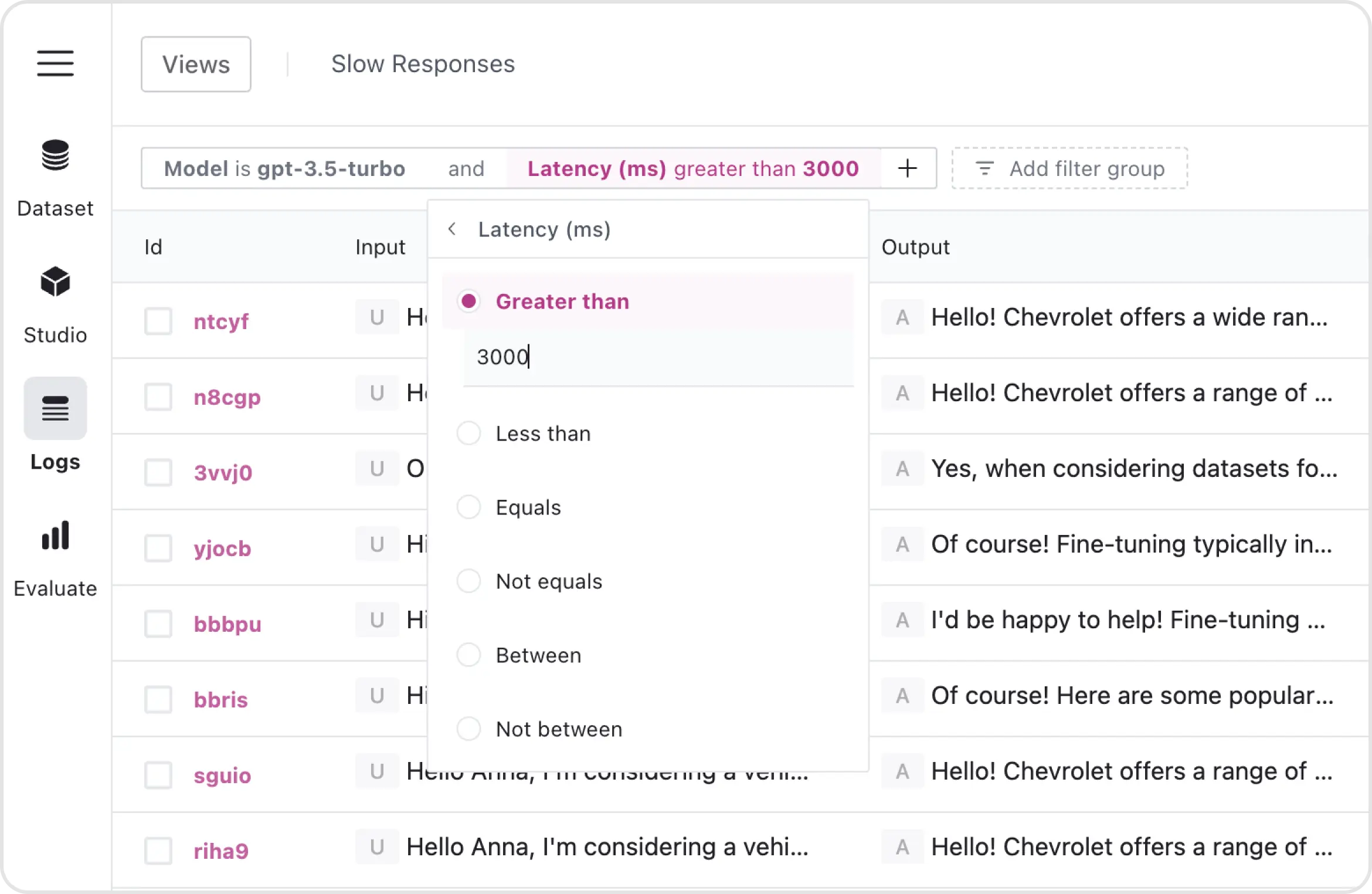
Step 4: Create a Dataset
ContentBoost imports the filtered logs and creates a new fine-tuning dataset. This dataset will serve as the training data for their open-source model. By including logs of high-performing content, they make sure the model learns only from the best examples.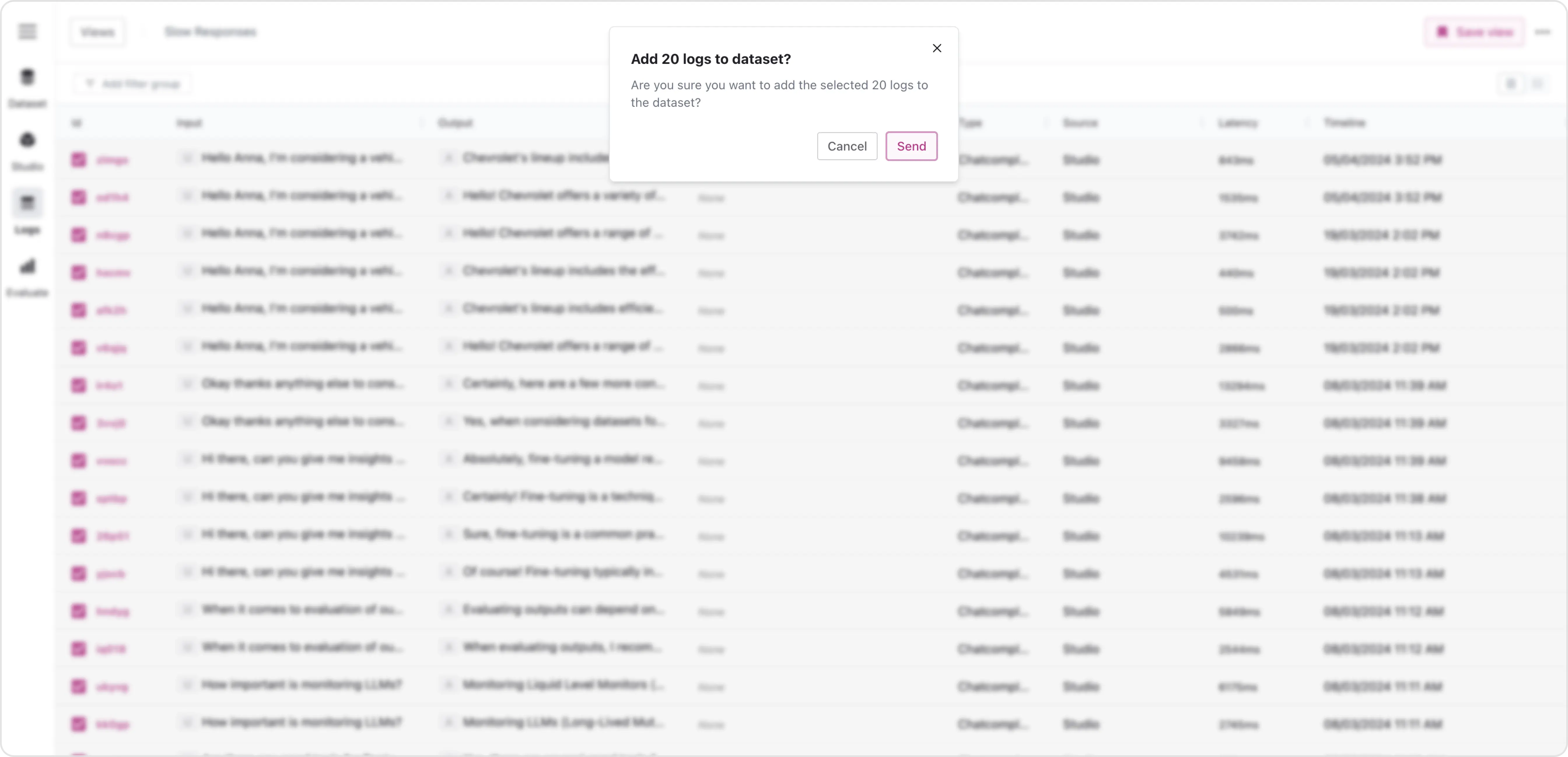
Step 5: Fine-Tune an Open-Source Model
ContentBoost selects Mixtral-8x7b-instruct as their open-source base model of choice, and uses the newly created dataset for fine-tuning. They configure training parameters as needed and start the training process. Depending on the size of the dataset and model, this may take a few hours. Once fine-tuning is completed, they receive a notification.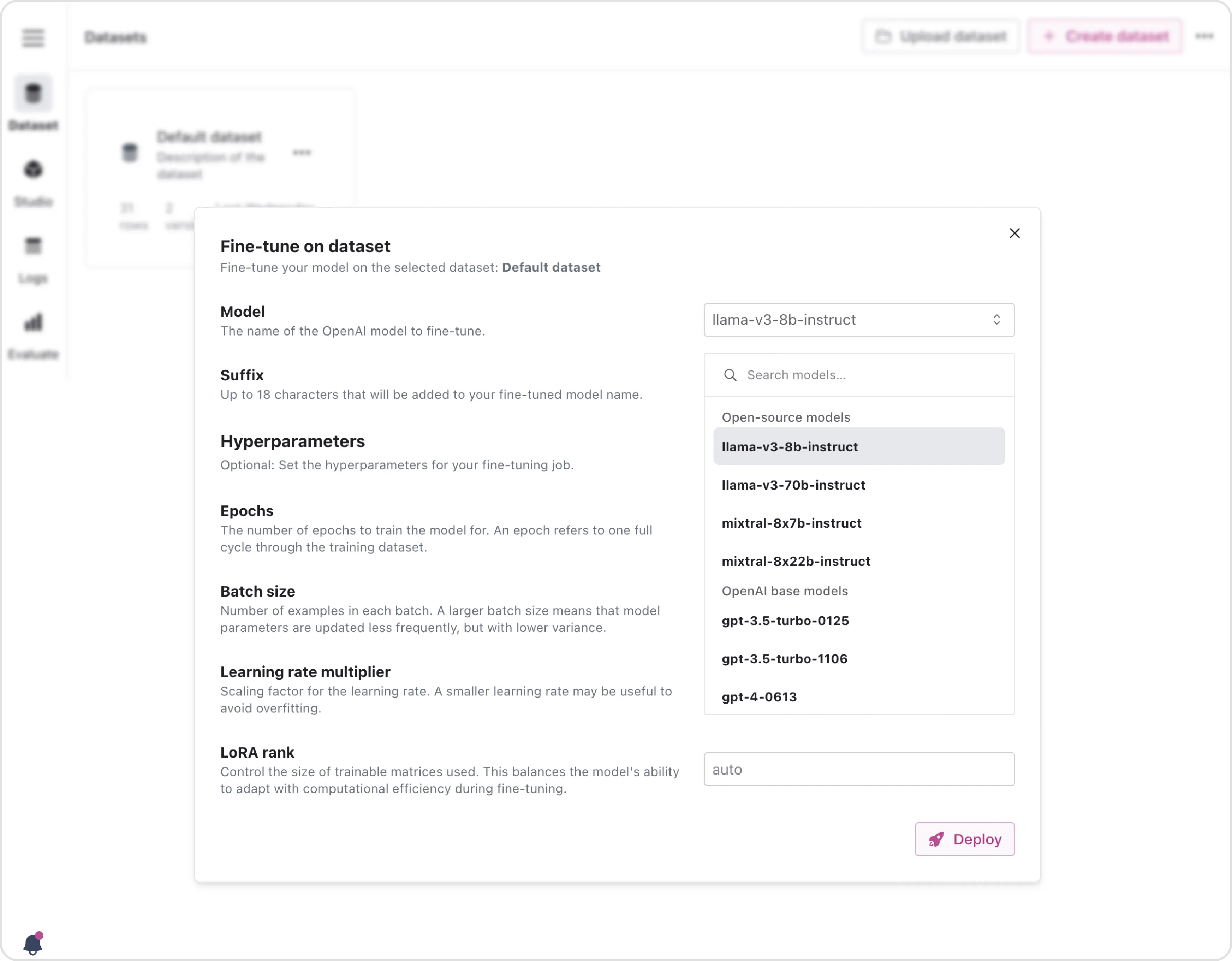
Step 6: Evaluate and Deploy
ContentBoost evaluates the performance of the newly fine-tuned Mixtral model and compares it against the original GPT-4 Turbo model in the FinetuneDB Studio. They use evaluation datasets to thoroughly test their use case. If the performance is satisfactory, they deploy the open-source model to production by using the FinetuneDB inferenece API. The model is now ready to generate marketing content and SEO-optimized articles for their customers.
Step 7: Continuous Improvement
ContentBoost regularly evaluates their model outputs, which are tracked in the Log Viewer on FinetuneDB, and adds new production data to the dataset to cover edge cases. They use the FinetuneDB evaluation workflow to review captured logs, improve them, and integrate them back into the dataset for further fine-tuning, ensuring continuous model performance enhancement.Evaluation
Measure and improve the quality of model outputs with evaluations.
Step 8: Personalized Fine-Tuning
For larger clients, ContentBoost fine-tunes the model to reflect their specific writing style and tone of voice. Using FinetuneDB’s infrastructure, they create multiple projects and datasets for each client. They gather client-specific content data and fine-tune the existing open-source model to ensure the generated content aligns perfectly with the client’s brand and style guidelines.